
70-475 Exam Questions - Online Test
70-475 Premium VCE File

150 Lectures, 20 Hours

microsoft 70 475 are updated and microsoft 70 475 are verified by experts. Once you have completely prepared with our 70 475 exam you will be ready for the real 70-475 exam without a problem. We have microsoft 70 475. PASSED exam 70 475 First attempt! Here What I Did.
Online Microsoft 70-475 free dumps demo Below:
NEW QUESTION 1
You plan to create a Microsoft Azure Data Factory pipeline that will connect to an Azure HDInsight cluster that uses Apache Spark.
You need to recommend which file format must be used by the pipeline. The solution must meet the following requirements: Store data in the columnar format Support compression
Store data in the columnar format Support compression
Which file format should you recommend?
- A. XML
- B. AVRO
- C. text
- D. Parquet
Answer: D
Explanation: Apache Parquet is a columnar storage format available to any project in the Hadoop ecosystem, regardless of the choice of data processing framework, data model or programming language.
Apache Parquet supports compression.
NEW QUESTION 2
You plan to deploy a Hadoop cluster that includes a Hive installation.
Your company identifies the following requirements for the planned deployment:  During the creation of the cluster nodes, place JAR files in the clusters. Decouple the Hive metastore lifetime from the cluster lifetime. Provide anonymous access to the cluster nodes.
During the creation of the cluster nodes, place JAR files in the clusters. Decouple the Hive metastore lifetime from the cluster lifetime. Provide anonymous access to the cluster nodes.
You need to identify which technology must be used for each requirement.
Which technology should you identify for each requirement? To answer, drag the appropriate technologies to the correct requirements. Each technology may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
Answer:
Explanation: 
NEW QUESTION 3
You plan to design a solution to gather data from 5,000 sensors that are deployed to multiple machines. The sensors generate events that contain data on the health status of the machines.
You need to create a new Microsoft Azure event hub to collect the event data.
Which command should you run? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
Answer:
Explanation: 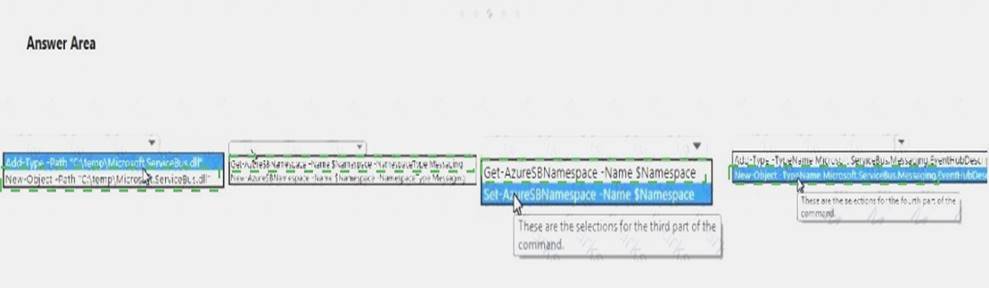
NEW QUESTION 4
You have a Microsoft Azure data factory named ADF1 that contains a pipeline named Pipeline1. You plan to automate updates to Pipeline1.
You need to build the URL that must be called to update the pipeline from the REST API.
How should you complete the URL? To answer, drag the appropriate URL elements to the correct locations. Each URL element may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Answer:
Explanation: 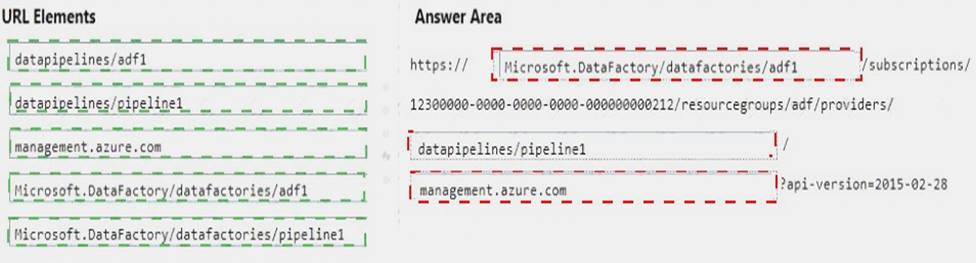
NEW QUESTION 5
You have a Microsoft Azure Stream Analytics job that contains several pipelines.
The Stream Analytics job is configured to trigger an alert when the sale of products in specific categories exceeds a specified threshold.
You plan to change the product-to-category mappings next month to meet future business requirements.
You need to create the new product-to-category mappings to prepare for the planned change. The solution must ensure that the Stream Analytics job only uses the new product-to-category mappings when the
mappings are ready to be activated.
Which naming structure should you use for the file that contains the product-to-category mappings?
- A. Use any date after the day the file becomes active.
- B. Use any date before the day the categories become active.
- C. Use the date and hour that the categories are to become active.
- D. Use the current date and time.
Answer: C
NEW QUESTION 6
You are creating a retail analytics system for a company that manufactures equipment.
The company manufactures thousands of loT devices that report their status over the Internet
You need to recommend a solution to visualize notifications from the devices on a mobile-ready dashboard. Which three actions should you recommend be performed in sequence? To answer, move the appropriate
actions from the list of actions to the answer area and arrange them in the correct order.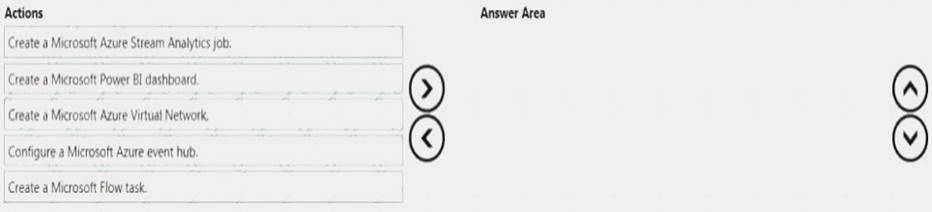
Answer:
Explanation: References: https://docs.microsoft.com/en-us/azure/iot-hub/iot-hub-live-data-visualization-in-power-bi
NEW QUESTION 7
You have a Microsoft Azure Data Factory pipeline that contains an input dataset.
You need to ensure that the data from Azure Table Storage is copied only if the table contains 1,000 records or more.
Which policy setting should you use in JSON?
- A. Option A
- B. Option B
- C. Option C
- D. Option D
Answer: B
Explanation: The following JSON defines a Linux-based on-demand HDInsight linked service. The Data Factory service automatically creates a Linux-based HDInsight cluster to process the required activity.
{
"name": "HDInsightOnDemandLinkedService", "properties": {
"type": "HDInsightOnDemand", "typeProperties": { "clusterType": "hadoop", "clusterSize": 1,
"timeToLive": "00:15:00", "hostSubscriptionId": "<subscription ID>", "servicePrincipalId": "<service principal ID>", "servicePrincipalKey": {
"value": "<service principal key>", "type": "SecureString"
},
"tenant": "<tenent id>",
"clusterResourceGroup": "<resource group name>", "version": "3.6",
"osType": "Linux", "linkedServiceName": {
"referenceName": "AzureStorageLinkedService", "type": "LinkedServiceReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>", "type": "IntegrationRuntimeReference"
}
}
}
References: https://docs.microsoft.com/en-us/azure/data-factory/compute-linked-services
NEW QUESTION 8
You need to design the data load process from DB1 to DB2. Which data import technique should you use in the design?
- A. PolyBase
- B. SQL Server Integration Services (SSIS)
- C. the Bulk Copy Program (BCP)
- D. the BULK INSERT statement
Answer: C
NEW QUESTION 9
You plan to implement a Microsoft Azure Data Factory pipeline. The pipeline will have custom business logic that requires a custom processing step.
You need to implement the custom processing step by using C#.
Which interface and method should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.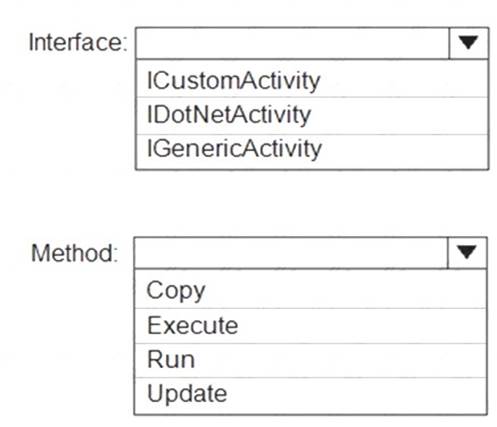
Answer:
Explanation: References:
https://github.com/MicrosoftDocs/azure-docs/blob/master/articles/data-factory/v1/data-factory-use-custom-activ
NEW QUESTION 10
You have structured data that resides in Microsoft Azure Blob Storage.
You need to perform a rapid interactive analysis of the data and to generate visualizations of the data.
What is the best type of Azure HDInsight cluster to use to achieve the goal? More than one answer choice may achieve the goal. Select the BEST answer.
- A. Apache Storm
- B. Apache HBase
- C. Apache Hadoop
- D. Apache Spark
Answer: D
Explanation:
Reference: https://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-hadoop-provision-linux-clusters
NEW QUESTION 11
You are building a streaming data analysis solution that will process approximately 1 TB of data weekly. You plan to use Microsoft Azure Stream Analytics to create alerts on real-time data. The data must be preserved for deeper analysis at a later date.
You need to recommend a storage solution for the alert data. The solution must meet the following requirements: Support scaling up without any downtime Minimize data storage costs.
What should you recommend using to store the data?
- A. Azure Data Lake
- B. Azure SQL Database
- C. Azure SQL Data Warehouse
- D. Apache Kafka
Answer: A
NEW QUESTION 12
A company named Fabrikam, Inc. has a Microsoft Azure web app. Billions of users visit the app daily.
The web app logs all user activity by using text files in Azure Blob storage. Each day, approximately 200 GB of text files are created.
Fabrikam uses the log files from an Apache Hadoop cluster on Azure DHlnsight.
You need to recommend a solution to optimize the storage of the log files for later Hive use.
What is the best property to recommend adding to the Hive table definition to achieve the goal? More than one answer choice may achieve the goal. Select the BEST answer.
- A. STORED AS RCFILE
- B. STORED AS GZIP
- C. STORED AS ORC
- D. STORED AS TEXTFILE
Answer: C
Explanation: The Optimized Row Columnar (ORC) file format provides a highly efficient way to store Hive data. It was designed to overcome limitations of the other Hive file formats. Using ORC files improves performance when Hive is reading, writing, and processing data.
Compared with RCFile format, for example, ORC file format has many advantages such as: a single file as the output of each task, which reduces the NameNode's load Hive type support including datetime, decimal, and the complex types (struct, list, map, and union) light-weight indexes stored within the file skip row groups that don't pass predicate filtering seek to a given row block-mode compression based on data type run-length encoding for integer columns dictionary encoding for string columns concurrent reads of the same file using separate RecordReaders ability to split files without scanning for markers bound the amount of memory needed for reading or writing metadata stored using Protocol Buffers, which allows addition and removal of fields
NEW QUESTION 13
You implement DB2.
You need to configure the tables in DB2 to host the data from DB1. The solution must meet the requirements for DB2.
Which type of table and history table storage should you use for the tables? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation: From Scenario: Relecloud plans to implement a data warehouse named DB2. Box 1: Temporal table
From Scenario:
Relecloud identifies the following requirements for DB2:
Users must be able to view previous versions of the data in DB2 by using aggregates. DB2 must be able to store more than 40 TB of data.
A system-versioned temporal table is a new type of user table in SQL Server 2021, designed to keep a full history of data changes and allow easy point in time analysis. A temporal table also contains a reference to another table with a mirrored schema. The system uses this table to automatically store the previous version of the row each time a row in the temporal table gets updated or deleted. This additional table is referred to as the history table, while the main table that stores current (actual) row versions is referred to as the current table or simply as the temporal table.
NEW QUESTION 14
You have a pipeline that contains an input dataset in Microsoft Azure Table Storage and an output dataset in Azure Blob storage. You have the following JSON data.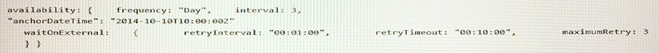
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the JSON data.
NOTE: Each correct selection is worth one point.
Answer:
Explanation: Box 1: Every three days at 10.00
anchorDateTime defines the absolute position in time used by the scheduler to compute dataset slice boundaries.
"frequency": "<Specifies the time unit for data slice production. Supported frequency: Minute, Hour, Day, Week, Month>",
"interval": "<Specifies the interval within the defined frequency. For example, frequency set to 'Hour' and interval set to 1 indicates that new data slices should be produced hourly>
Box 2: Every minute up to three times.
retryInterval is the wait time between a failure and the next attempt. This setting applies to present time. If the previous try failed, the next try is after the retryInterval period.
Example: 00:01:00 (1 minute)
Example: If it is 1:00 PM right now, we begin the first try. If the duration to complete the first validation check is 1 minute and the operation failed, the next retry is at 1:00 + 1min (duration) + 1min (retry interval) = 1:02 PM.
For slices in the past, there is no delay. The retry happens immediately. retryTimeout is the timeout for each retry attempt.
maximumRetry is the number of times to check for the availability of the external data.
NEW QUESTION 15
You plan to deploy Microsoft Azure HDInsight clusters for business analytics and data pipelines. The clusters must meet the following requirements: Business users must use a language that is similar to SQL. The authoring of data pipelines must occur in a dataflow language. You need to identify which language must be used for each requirement.
Business users must use a language that is similar to SQL. The authoring of data pipelines must occur in a dataflow language. You need to identify which language must be used for each requirement.
Which languages should you identify? To answer, drag the appropriate languages to the correct requirements. Each language may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
Answer:
Explanation: 
NEW QUESTION 16
You are planning a solution that will have multiple data files stored in Microsoft Azure Blob storage every hour. Data processing will occur once a day at midnight only.
You create an Azure data factory that has blob storage as the input source and an Azure HD Insight activity that uses the input to create an output Hive table.
You need to identify a data slicing strategy for the data factory.
What should you identify? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
Answer:
Explanation: 
NEW QUESTION 17
You need to automate the creation of a new Microsoft Azure data factory.
What are three possible technologies that you can use? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point
- A. Azure PowerShell cmdlets
- B. the SOAP service
- C. T-SQL statements
- D. the REST API
- E. the Microsoft .NET framework class library
Answer: ADE
Explanation: https://docs.microsoft.com/en-us/azure/data-factory/data-factory-introduction
100% Valid and Newest Version 70-475 Questions & Answers shared by Surepassexam, Get Full Dumps HERE: https://www.surepassexam.com/70-475-exam-dumps.html (New 102 Q&As)
- All About High quality 70-347 practice test
- The Refresh Guide To 70-486 examcollection
- Microsoft 70-341 Dumps Questions 2021
- how many questions of 70-467 practice test?
- What Printable MS-203 Dumps Questions Is
- The Secret of Microsoft 70-488 pdf
- Realistic Windows 70-685 pdf
- Renew Microsoft 70-462 exam dumps
- 100% Correct AZ-102 Study Guides 2021
- Microsoft AZ-220 Guidance 2021