
DP-200 Exam Questions - Online Test
DP-200 Premium VCE File

150 Lectures, 20 Hours

Proper study guides for Most recent Microsoft Implementing an Azure Data Solution certified begins with Microsoft DP-200 preparation products which designed to deliver the Downloadable DP-200 questions by making you pass the DP-200 test at your first time. Try the free DP-200 demo right now.
Free demo questions for Microsoft DP-200 Exam Dumps Below:
NEW QUESTION 1
You develop data engineering solutions for a company.
You need to ingest and visualize real-time Twitter data by using Microsoft Azure.
Which three technologies should you use? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. Event Grid topic
- B. Azure Stream Analytics Job that queries Twitter data from an Event Hub
- C. Azure Stream Analytics Job that queries Twitter data from an Event Grid
- D. Logic App that sends Twitter posts which have target keywords to Azure
- E. Event Grid subscription
- F. Event Hub instance
Answer: BDF
Explanation:
You can use Azure Logic apps to send tweets to an event hub and then use a Stream Analytics job to read from event hub and send them to PowerBI.
References:
https://community.powerbi.com/t5/Integrations-with-Files-and/Twitter-streaming-analytics-step-by-step/td-p/95
NEW QUESTION 2
You develop data engineering solutions for a company. You must migrate data from Microsoft Azure Blob storage to an Azure SQL Data Warehouse for further transformation. You need to implement the solution.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Step 1: Provision an Azure SQL Data Warehouse instance. Create a data warehouse in the Azure portal.
Step 2: Connect to the Azure SQL Data warehouse by using SQL Server Management Studio Connect to the data warehouse with SSMS (SQL Server Management Studio)
Step 3: Build external tables by using the SQL Server Management Studio
Create external tables for data in Azure blob storage.
You are ready to begin the process of loading data into your new data warehouse. You use external tables to load data from the Azure storage blob.
Step 4: Run Transact-SQL statements to load data.
You can use the CREATE TABLE AS SELECT (CTAS) T-SQL statement to load the data from Azure Storage Blob into new tables in your data warehouse.
References:
https://github.com/MicrosoftDocs/azure-docs/blob/master/articles/sql-data-warehouse/load-data-from-azure-blo
NEW QUESTION 3
You manage the Microsoft Azure Databricks environment for a company. You must be able to access a private Azure Blob Storage account. Data must be available to all Azure Databricks workspaces. You need to provide the data access.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Step 1: Create a secret scope Step 2: Add secrets to the scope
Note: dbutils.secrets.get(scope = "<scope-name>", key = "<key-name>") gets the key that has been stored as a secret in a secret scope.
Step 3: Mount the Azure Blob Storage container
You can mount a Blob Storage container or a folder inside a container through Databricks File System - DBFS. The mount is a pointer to a Blob Storage container, so the data is never synced locally.
Note: To mount a Blob Storage container or a folder inside a container, use the following command:
Python dbutils.fs.mount(
source = "wasbs://<your-container-name>@<your-storage-account-name>.blob.core.windows.net", mount_point = "/mnt/<mount-name>",
extra_configs = {"<conf-key>":dbutils.secrets.get(scope = "<scope-name>", key = "<key-name>")}) where:
dbutils.secrets.get(scope = "<scope-name>", key = "<key-name>") gets the key that has been stored as a secret in a secret scope.
References:
https://docs.databricks.com/spark/latest/data-sources/azure/azure-storage.html
NEW QUESTION 4
You are designing a new Lambda architecture on Microsoft Azure. The real-time processing layer must meet the following requirements: Ingestion: Receive millions of events per second Act as a fully managed Platform-as-a-Service (PaaS) solution
Receive millions of events per second Act as a fully managed Platform-as-a-Service (PaaS) solution  Integrate with Azure Functions
Integrate with Azure Functions
Stream processing: Process on a per-job basis Provide seamless connectivity with Azure services Use a SQL-based query language
Analytical data store: Act as a managed service Use a document store Provide data encryption at rest
You need to identify the correct technologies to build the Lambda architecture using minimal effort. Which technologies should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Box 1: Azure Event Hubs
This portion of a streaming architecture is often referred to as stream buffering. Options include Azure Event Hubs, Azure IoT Hub, and Kafka.
NEW QUESTION 5
You are creating a managed data warehouse solution on Microsoft Azure.
You must use PolyBase to retrieve data from Azure Blob storage that resides in parquet format and toad the data into a large table called FactSalesOrderDetails.
You need to configure Azure SQL Data Warehouse to receive the data.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.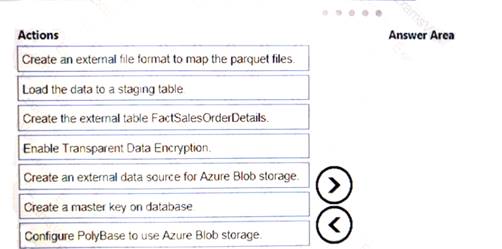
- A. Mastered
- B. Not Mastered
Answer: A
Explanation: 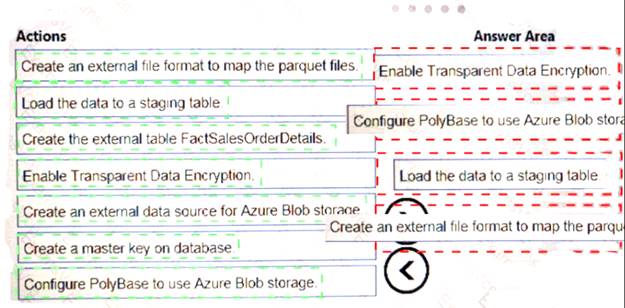
NEW QUESTION 6
Your company uses several Azure HDInsight clusters.
The data engineering team reports several errors with some application using these clusters. You need to recommend a solution to review the health of the clusters.
What should you include in you recommendation?
- A. Azure Automation
- B. Log Analytics
- C. Application Insights
Answer: C
NEW QUESTION 7
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
A company uses Azure Data Lake Gen 1 Storage to store big data related to consumer behavior. You need to implement logging.
Solution: Use information stored m Azure Active Directory reports.
Does the solution meet the goal?
- A. Yes
- B. No
Answer: B
NEW QUESTION 8
You manage security for a database that supports a line of business application. Private and personal data stored in the database must be protected and encrypted. You need to configure the database to use Transparent Data Encryption (TDE).
Which five actions should you perform in sequence? To answer, select the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Step 1: Create a master key
Step 2: Create or obtain a certificate protected by the master key Step 3: Set the context to the company database
Step 4: Create a database encryption key and protect it by the certificate Step 5: Set the database to use encryption
Example code: USE master; GO
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<UseStrongPasswordHere>';
go
CREATE CERTIFICATE MyServerCert WITH SUBJECT = 'My DEK Certificate'; go
USE AdventureWorks2012; GO
CREATE DATABASE ENCRYPTION KEY WITH ALGORITHM = AES_128
ENCRYPTION BY SERVER CERTIFICATE MyServerCert; GO
ALTER DATABASE AdventureWorks2012 SET ENCRYPTION ON;
GO
References:
https://docs.microsoft.com/en-us/sql/relational-databases/security/encryption/transparent-data-encryption
NEW QUESTION 9
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution. Determine whether the solution meets the stated goals.
You develop a data ingestion process that will import data to a Microsoft Azure SQL Data Warehouse. The data to be ingested resides in parquet files stored in an Azure Data lake Gen 2 storage account.
You need to load the data from the Azure Data Lake Gen 2 storage account into the Azure SQL Data Warehouse.
Solution:
1. Create an external data source pointing to the Azure storage account
2. Create a workload group using the Azure storage account name as the pool name
3. Load the data using the INSERT…SELECT statement
Does the solution meet the goal?
- A. Yes
- B. No
Answer: B
Explanation:
You need to create an external file format and external table using the external data source. You then load the data using the CREATE TABLE AS SELECT statement.
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-load-from-azure-data-lake-store
NEW QUESTION 10
You manage a Microsoft Azure SQL Data Warehouse Gen 2.
Users report slow performance when they run commonly used queries. Users do not report performance changes for infrequently used queries
You need to monitor resource utilization to determine the source of the performance issues. Which metric should you monitor?
- A. Cache used percentage
- B. Local tempdb percentage
- C. WU percentage
- D. CPU percentage
Answer: B
NEW QUESTION 11
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some questions sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You need to configure data encryption for external applications. Solution:
1. Access the Always Encrypted Wizard in SQL Server Management Studio
2. Select the column to be encrypted
3. Set the encryption type to Randomized
4. Configure the master key to use the Windows Certificate Store
5. Validate configuration results and deploy the solution Does the solution meet the goal?
- A. Yes
- B. No
Answer: B
Explanation:
Use the Azure Key Vault, not the Windows Certificate Store, to store the master key.
Note: The Master Key Configuration page is where you set up your CMK (Column Master Key) and select the key store provider where the CMK will be stored. Currently, you can store a CMK in the Windows certificate store, Azure Key Vault, or a hardware security module (HSM).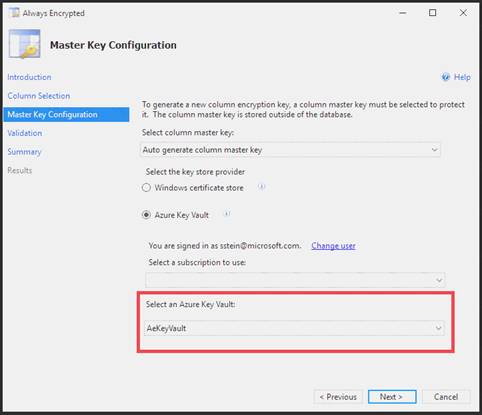
References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-always-encrypted-azure-key-vault
NEW QUESTION 12
You are the data engineer tor your company. An application uses a NoSQL database to store data. The database uses the key-value and wide-column NoSQL database type.
Developers need to access data in the database using an API.
You need to determine which API to use for the database model and type.
Which two APIs should you use? Each correct answer presents a complete solution. NOTE: Each correct selection s worth one point.
- A. Table API
- B. MongoDB API
- C. Gremlin API
- D. SQL API
- E. Cassandra API
Answer: BE
Explanation:
B: Azure Cosmos DB is the globally distributed, multimodel database service from Microsoft for mission-critical applications. It is a multimodel database and supports document, key-value, graph, and columnar data models.
E: Wide-column stores store data together as columns instead of rows and are optimized for queries over large datasets. The most popular are Cassandra and HBase.
References:
https://docs.microsoft.com/en-us/azure/cosmos-db/graph-introduction https://www.mongodb.com/scale/types-of-nosql-databases
NEW QUESTION 13
You configure monitoring for a Microsoft Azure SQL Data Warehouse implementation. The implementation uses PolyBase to load data from comma-separated value (CSV) files stored in Azure Data Lake Gen 2 using an external table.
Files with an invalid schema cause errors to occur. You need to monitor for an invalid schema error. For which error should you monitor?
- A. EXTERNAL TABLE access failed due to internal error: 'Java exception raised on call to HdfsBridge_Connect: Error[com.microsoft.polybase.client.KerberosSecureLogin] occurred while accessing external files.'
- B. EXTERNAL TABLE access failed due to internal error: 'Java exception raised on call to HdfsBridge_Connect: Error [No FileSystem for scheme: wasbs] occurred while accessing external file.'
- C. Cannot execute the query "Remote Query" against OLE DB provider "SQLNCLI11": for linked server "(null)", Query aborted- the maximum reject threshold (orows) was reached while regarding from an external source: 1 rows rejected out of total 1 rows processed.
- D. EXTERNAL TABLE access failed due to internal error: 'Java exception raised on call to HdfsBridge_Connect: Error [Unable to instantiate LoginClass] occurredwhile accessing external files.'
Answer: C
Explanation:
Customer Scenario:
SQL Server 2021 or SQL DW connected to Azure blob storage. The CREATE EXTERNAL TABLE DDL points to a directory (and not a specific file) and the directory contains files with different schemas.
SSMS Error:
Select query on the external table gives the following error: Msg 7320, Level 16, State 110, Line 14
Cannot execute the query "Remote Query" against OLE DB provider "SQLNCLI11" for linked server "(null)". Query aborted-- the maximum reject threshold (0 rows) was reached while reading from an external source: 1 rows rejected out of total 1 rows processed.
Possible Reason:
The reason this error happens is because each file has different schema. The PolyBase external table DDL when pointed to a directory recursively reads all the files in that directory. When a column or data type mismatch happens, this error could be seen in SSMS.
Possible Solution:
If the data for each table consists of one file, then use the filename in the LOCATION section prepended by the directory of the external files. If there are multiple files per table, put each set of files into different directories in Azure Blob Storage and then you can point LOCATION to the directory instead of a particular file. The latter suggestion is the best practices recommended by SQLCAT even if you have one file per table.
NEW QUESTION 14
Your company uses Azure SQL Database and Azure Blob storage.
All data at rest must be encrypted by using the company's own key. The solution must minimize administrative effort and the impact to applications which use the database.
You need to configure security.
What should you implement? To answer, select the appropriate option in the answer area. NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation: 
NEW QUESTION 15
You manage a process that performs analysis of daily web traffic logs on an HDInsight cluster. Each of 250 web servers generates approximately gigabytes (GB) of log data each day. All log data is stored in a single folder in Microsoft Azure Data Lake Storage Gen 2.
You need to improve the performance of the process.
Which two changes should you make? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
- A. Combine the daily log files for all servers into one file
- B. Increase the value of the mapreduce.map.memory parameter
- C. Move the log files into folders so that each day’s logs are in their own folder
- D. Increase the number of worker nodes
- E. Increase the value of the hive.tez.container.size parameter
Answer: AC
Explanation:
A: Typically, analytics engines such as HDInsight and Azure Data Lake Analytics have a per-file overhead. If you store your data as many small files, this can negatively affect performance. In general, organize your data into larger sized files for better performance (256MB to 100GB in size). Some engines and applications might have trouble efficiently processing files that are greater than 100GB in size.
C: For Hive workloads, partition pruning of time-series data can help some queries read only a subset of the data which improves performance.
Those pipelines that ingest time-series data, often place their files with a very structured naming for files and folders. Below is a very common example we see for data that is structured by date:
DataSetYYYYMMDDdatafile_YYYY_MM_DD.tsv
Notice that the datetime information appears both as folders and in the filename. References:
https://docs.microsoft.com/en-us/azure/storage/blobs/data-lake-storage-performance-tuning-guidance
NEW QUESTION 16
Your company has on-premises Microsoft SQL Server instance.
The data engineering team plans to implement a process that copies data from the SQL Server instance to Azure Blob storage. The process must orchestrate and manage the data lifecycle.
You need to configure Azure Data Factory to connect to the SQL Server instance.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation: 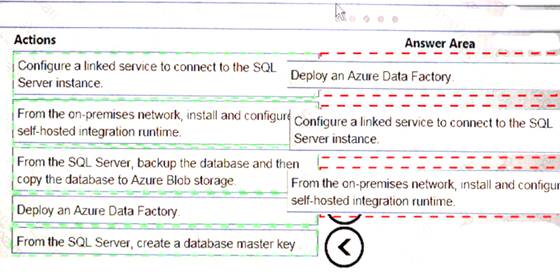
NEW QUESTION 17
You manage a financial computation data analysis process. Microsoft Azure virtual machines (VMs) run the process in daily jobs, and store the results in virtual hard drives (VHDs.)
The VMs product results using data from the previous day and store the results in a snapshot of the VHD. When a new month begins, a process creates a new VHD.
You must implement the following data retention requirements:  Daily results must be kept for 90 days
Daily results must be kept for 90 days Data for the current year must be available for weekly reports Data from the previous 10 years must be stored for auditing purposes Data required for an audit must be produced within 10 days of a request. You need to enforce the data retention requirements while minimizing cost.
Data for the current year must be available for weekly reports Data from the previous 10 years must be stored for auditing purposes Data required for an audit must be produced within 10 days of a request. You need to enforce the data retention requirements while minimizing cost.
How should you configure the lifecycle policy? To answer, drag the appropriate JSON segments to the correct locations. Each JSON segment may be used once, more than once, or not at all. You may need to drag the split bat between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
The Set-AzStorageAccountManagementPolicy cmdlet creates or modifies the management policy of an Azure Storage account.
Example: Create or update the management policy of a Storage account with ManagementPolicy rule objects.
Action -BaseBlobAction Delete -daysAfterModificationGreaterThan 100
PS C:>$action1 = Add-AzStorageAccountManagementPolicyAction -InputObject $action1 -BaseBlobAction TierToArchive -daysAfterModificationGreaterThan 50
PS C:>$action1 = Add-AzStorageAccountManagementPolicyAction -InputObject $action1 -BaseBlobAction TierToCool -daysAfterModificationGreaterThan 30
PS C:>$action1 = Add-AzStorageAccountManagementPolicyAction -InputObject $action1 -SnapshotAction Delete -daysAfterCreationGreaterThan 100
PS C:>$filter1 = New-AzStorageAccountManagementPolicyFilter -PrefixMatch ab,cd
PS C:>$rule1 = New-AzStorageAccountManagementPolicyRule -Name Test -Action $action1 -Filter $filter1
PS C:>$action2 = Add-AzStorageAccountManagementPolicyAction -BaseBlobAction Delete
-daysAfterModificationGreaterThan 100
PS C:>$filter2 = New-AzStorageAccountManagementPolicyFilter References:
https://docs.microsoft.com/en-us/powershell/module/az.storage/set-azstorageaccountmanagementpolicy
NEW QUESTION 18
A company runs Microsoft SQL Server in an on-premises virtual machine (VM).
You must migrate the database to Azure SQL Database. You synchronize users from Active Directory to Azure Active Directory (Azure AD).
You need to configure Azure SQL Database to use an Azure AD user as administrator. What should you configure?
- A. For each Azure SQL Database, set the Access Control to administrator.
- B. For the Azure SQL Database server, set the Active Directory to administrator.
- C. For each Azure SQL Database, set the Active Directory administrator role.
- D. For the Azure SQL Database server, set the Access Control to administrator.
Answer: A
NEW QUESTION 19
You implement 3 Azure SQL Data Warehouse instance.
You plan to migrate the largest fact table to Azure SQL Data Warehouse The table resides on Microsoft SQL Server on-premises and e 10 terabytes (TB) in size.
Incoming queues use the primary key Sale Key column to retrieve data as displayed in the following table: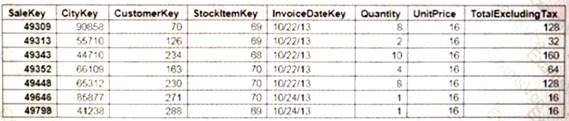
You need to distribute the fact table across multiple nodes to optimize performance of the table. Which technology should you use?
- A. hash distributed table with clustered ColumnStore index
- B. hash distributed table with clustered index
- C. heap table with distribution replicate
- D. round robin distributed table with clustered index
- E. round robin distributed table with clustered ColumnStore index
Answer: A
NEW QUESTION 20
Note: This question is part of series of questions that present the same scenario. Each question in the series contain a unique solution. Determine whether the solution meets the stated goals.
You develop data engineering solutions for a company.
A project requires the deployment of resources to Microsoft Azure for batch data processing on Azure
HDInsight. Batch processing will run daily and must: Scale to minimize costs
Be monitored for cluster performance
You need to recommend a tool that will monitor clusters and provide information to suggest how to scale. Solution: Download Azure HDInsight cluster logs by using Azure PowerShell.
Does the solution meet the goal?
- A. Yes
- B. No
Answer: B
Explanation:
Reference:
Instead monitor clusters by using Azure Log Analytics and HDInsight cluster management solutions. References:
https://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-hadoop-oms-log-analytics-tutorial
NEW QUESTION 21
......
Thanks for reading the newest DP-200 exam dumps! We recommend you to try the PREMIUM Dumpscollection DP-200 dumps in VCE and PDF here: http://www.dumpscollection.net/dumps/DP-200/ (88 Q&As Dumps)
- The Secret of Microsoft 70-463 pdf
- The Up to the minute Guide To 70-487 exam question
- Most up-to-date 70-417 Exam Study Guides With New Update Exam Questions
- Renew Planning And Administering Microsoft Azure For SAP Workloads AZ-120 Free Exam
- Approved AZ-300 Bundle 2021
- The Up To The Immediate Present Guide To AZ-600 Dumps Questions
- Updated MS-201 Testing Material 2021
- Vivid SQL Server 70-461 exam dumps
- 100% Guarantee Windows Server 70-412 exam dumps
- 100% Correct AZ-102 Free Practice Questions 2021