
70-767 Exam Questions - Online Test
70-767 Premium VCE File

150 Lectures, 20 Hours

We provide real 70-767 exam questions and answers braindumps in two formats. Download PDF & Practice Tests. Pass Microsoft 70-767 Exam quickly & easily. The 70-767 PDF type is available for reading and printing. You can print more and practice many times. With the help of our Microsoft 70-767 dumps pdf and vce product and material, you can easily pass the 70-767 exam.
Online Microsoft 70-767 free dumps demo Below:
NEW QUESTION 1
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this sections, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Microsoft Azure SQL Data Warehouse instance. You run the following Transact-SQL statement:
The query fails to return results.
You need to determine why the query fails.
Solution: You run the following Transact-SQL statement:
Does the solution meet the goal?
- A. Yes
- B. No
Answer: B
Explanation:
To use submit_time we must use sys.dm_pdw_exec_requests table. References:
https://docs.microsoft.com/en-us/sql/relational-databases/system-dynamic-management-views/sys-dm-pdw-exec
NEW QUESTION 2
Your company has a Microsoft SQL Server data warehouse instance. The human resources department assigns all employees a unique identifier. You plan to store this identifier in a new table named Employee.
You create a new dimension to store information about employees by running the following Transact-SQL statement:
You have not added data to the dimension yet. You need to modify the dimension to implement a new column named [EmployeeKey]. The new column must use unique values.
How should you complete the Transact-SQL statements? To answer, select the appropriate Transact-SQL segments in the answer area.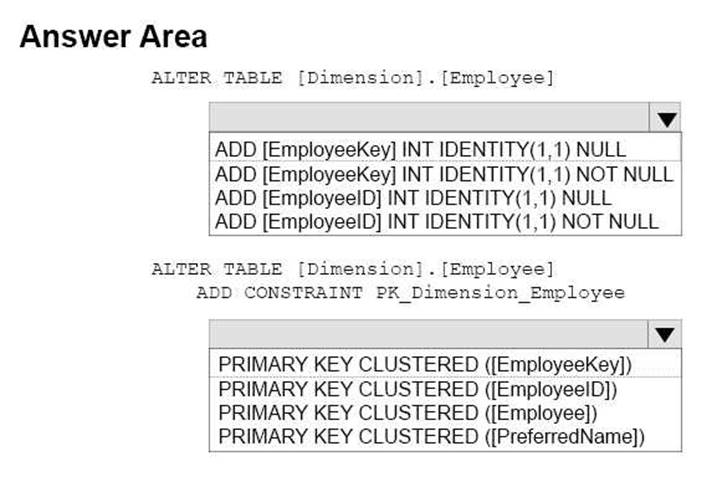
- A. Mastered
- B. Not Mastered
Answer: A
Explanation: 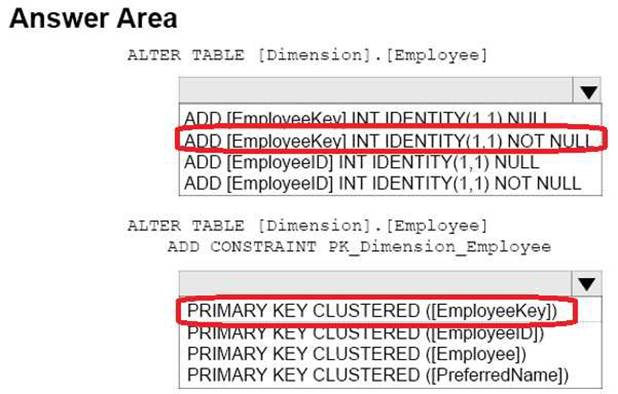
NEW QUESTION 3
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a Microsoft SQL Server data warehouse instance that supports several client applications. The data warehouse includes the following tables: Dimension.SalesTerritory, Dimension.Customer,
Dimension.Date, Fact.Ticket, and Fact.Order. The Dimension.SalesTerritory and Dimension.Customer tables are frequently updated. The Fact.Order table is optimized for weekly reporting, but the company wants to change it daily. The Fact.Order table is loaded by using an ETL process. Indexes have been added to the table over time, but the presence of these indexes slows data loading.
All data in the data warehouse is stored on a shared SAN. All tables are in a database named DB1. You have a second database named DB2 that contains copies of production data for a development environment. The data warehouse has grown and the cost of storage has increased. Data older than one year is accessed infrequently and is considered historical.
You have the following requirements: Implement table partitioning to improve the manageability of the data warehouse and to avoid the need to repopulate all transactional data each night. Use a partitioning strategy that is as granular as possible. - Partition the Fact.Order table and retain a total of seven years of data. - Partition the Fact.Ticket table and retain seven years of data. At the end of each month, the partition structure must apply a sliding window strategy to ensure that a new partition is available for the upcoming month, and that the oldest month of data is archived and removed. - Optimize data loading for the Dimension.SalesTerritory, Dimension.Customer, and Dimension.Date tables.- Maximize the performance during the data loading process for the Fact.Order partition. - Ensure that historical data remains online and available for querying. - Reduce ongoing storage costs while maintaining query performance for current data. You are not permitted to make changes to the client applications.
Implement table partitioning to improve the manageability of the data warehouse and to avoid the need to repopulate all transactional data each night. Use a partitioning strategy that is as granular as possible. - Partition the Fact.Order table and retain a total of seven years of data. - Partition the Fact.Ticket table and retain seven years of data. At the end of each month, the partition structure must apply a sliding window strategy to ensure that a new partition is available for the upcoming month, and that the oldest month of data is archived and removed. - Optimize data loading for the Dimension.SalesTerritory, Dimension.Customer, and Dimension.Date tables.- Maximize the performance during the data loading process for the Fact.Order partition. - Ensure that historical data remains online and available for querying. - Reduce ongoing storage costs while maintaining query performance for current data. You are not permitted to make changes to the client applications.
You need to configure the Fact.Order table.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.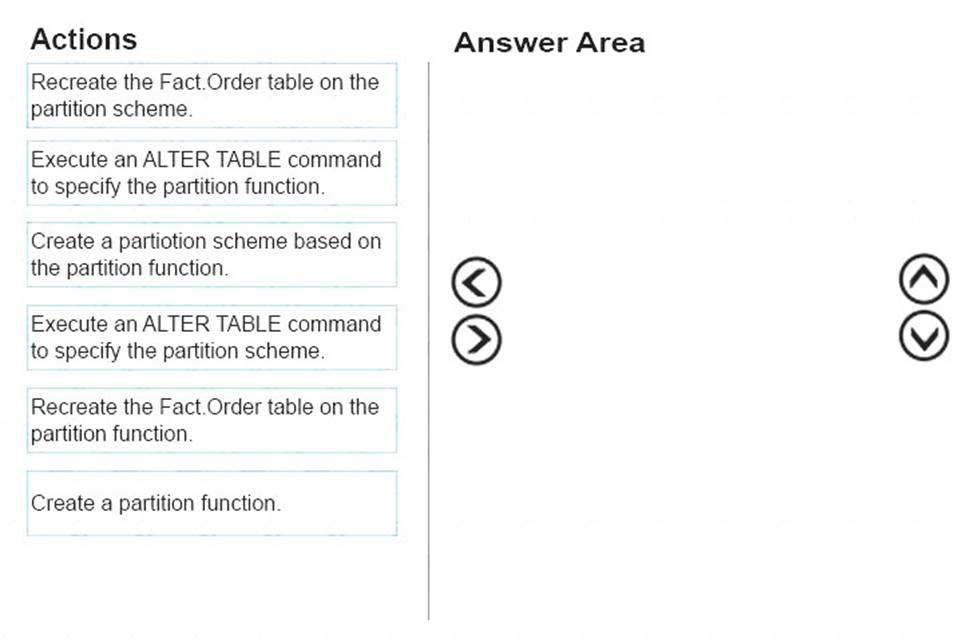
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
From scenario: Partition the Fact.Order table and retain a total of seven years of data. Maximize the performance during the data loading process for the Fact.Order partition.
Step 1: Create a partition function.
Using CREATE PARTITION FUNCTION is the first step in creating a partitioned table or index. Step 2: Create a partition scheme based on the partition function.
To migrate SQL Server partition definitions to SQL Data Warehouse simply: Step 3: Execute an ALTER TABLE command to specify the partition function.
References: https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-tables-partition
NEW QUESTION 4
You deploy a Microsoft Azure SQL Data Warehouse instance. The instance must be available eight hours each day.
You need to pause Azure resources when they are not in use to reduce costs.
What will be the impact of pausing resources? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
To save costs, you can pause and resume compute resources on-demand. For example, if you won't be using the database during the night and on weekends, you can pause it during those times, and resume it during the day. You won't be charged for DWUs while the database is paused.
When you pause a database:
Compute and memory resources are returned to the pool of available resources in the data center Data Warehouse Unit (DWU) costs are zero for the duration of the pause.
Data storage is not affected and your data stays intact.
SQL Data Warehouse cancels all running or queued operations. When you resume a database:
SQL Data Warehouse acquires compute and memory resources for your DWU setting. Compute charges for your DWUs resume.
Your data will be available.
You will need to restart your workload queries. References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-manage-compute-rest-api
NEW QUESTION 5
You have a data warehouse named DW1. All data files are located on drive E. You expect queries that pivot hundreds of millions of rows for each report. You need to modify the data files to minimize latency.
What should you do?
- A. Add more data files to DW1 on drive E.
- B. Add more data files to tempdb on drive E.
- C. Remove data files from tempdb
- D. Remove data files from DW1.
Answer: B
Explanation:
The number of files depends on the number of (logical) processors on the machine. As a general rule, if the number of logical processors is less than or equal to eight, use the same number of data files as logical processors. If the number of logical processors is greater than eight, use eight data files and then if contention continues, increase the number of data files by multiples of 4 until the contention is reduced to acceptable levels or make changes to the workload/code.
References: https://docs.microsoft.com/en-us/sql/relational-databases/databases/tempdb-database
NEW QUESTION 6
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You are developing a Microsoft SQL Server Integration Services (SSIS) package.
You are importing data from databases at retail stores into a central data warehouse. All stores use the same database schema.
The query being executed against the retail stores is shown below:
The data source property named IsSorted is set to True. The output of the transform must be sorted.
You need to add a component to the data flow. Which SSIS Toolbox item should you use?
- A. CDC Control task
- B. CDC Splitter
- C. Union All
- D. XML task
- E. Fuzzy Grouping
- F. Merge
- G. Merge Join
Answer: C
NEW QUESTION 7
You are implementing a Microsoft SQL Server data warehouse with a multi-dimensional data model. Orders are stored in a table named Factorder. The addresses that are associated with all orders are stored in a fact table named FactAddress. A key in the FoctAddress table specifies the type of address for an order.
You need to ensure that business users can examine the address data by either of the following:
• shipping address and billing address
• shipping address or billing address type Which data model should you use?
- A. star schema
- B. snowflake schema
- C. conformed dimension
- D. slowly changing dimension (SCD)
- E. fact table
- F. semi-additive measure
- G. non-additive measure
- H. dimension table reference relationship
Answer: H
NEW QUESTION 8
You have a data quality project that focuses on the Products catalog for the company. The data includes a product reference number.
The product reference should use the following format: Two letters followed by an asterisk and then four or five numbers. An example of a valid number is XX*55522. Any reference number that does not conform to the format must be rejected during the data cleansing.
You need to add a Data Quality Services (DQS) domain rule in the Products domain. Which rule should you use?
- A. value matches pattern ZA*9876[5]
- B. value matches pattern AZ[*]1234[5]
- C. value matches regular expression AZ[*]1234[5]
- D. value matches pattern [a-zA-Z][a-zA-Z]*[0-9][0-9] [0-9][0-9] [0-9]?
Answer: A
Explanation:
For a pattern matching rule:
Any letter (A…Z) can be used as a pattern for any letter; case insensitive Any digit (0…9) can be used as a pattern for any digit
Any special character, except a letter or a digit, can be used as a pattern for itself Brackets, [], define optional matching
Example: ABC:0000
This rule implies that the data will contain three parts: any three letters followed by a colon (:), which is again followed by any four digits.
NEW QUESTION 9
You have a Microsoft SQL Server Integration Services (SSIS) package that contains a Data Flow task as shown in the Data Flow exhibit. (Click the Exhibit button.)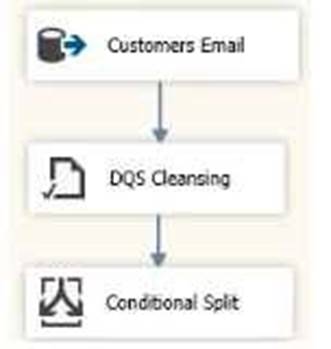
You install Data Quality Services (DQS) on the same server that hosts SSIS and deploy a knowledge base to manage customer email addresses. You add a DQS Cleansing transform to the Data Flow as shown in the Cleansing exhibit. (Click the Exhibit button.)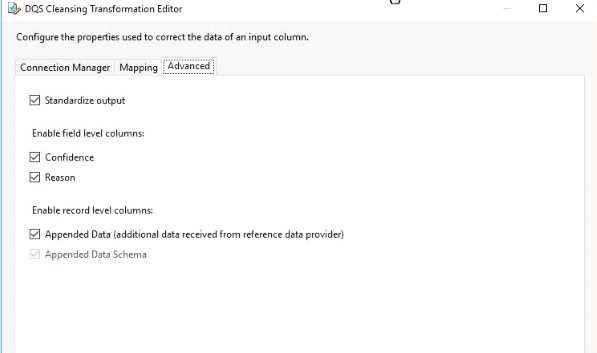
You create a Conditional Split transform as shown in the Splitter exhibit. (Click the Exhibit button.)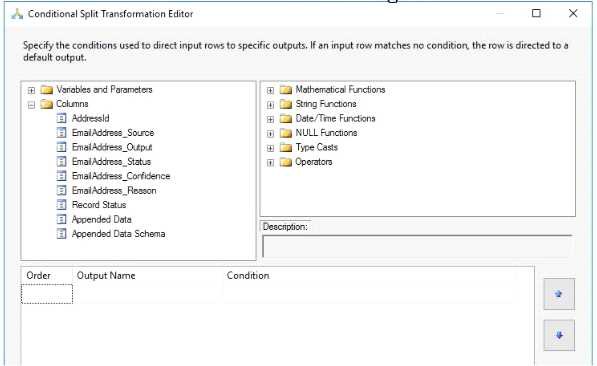
You need to split the output of the DQ5 Cleansing task to obtain only Correct values from the EmailAddress column. For each of the following statements, select Yes if the statement is true. Otherwise, select No.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation: 
NEW QUESTION 10
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
Your company uses Microsoft SQL Server to deploy a data warehouse to an environment that has a SQL Server Analysis Services (SSAS) instance. The data warehouse includes the Fact.Order table as shown in the following table definition. The table has no indexes.
You must minimize the amount of space that indexes for the Fact.Order table consume. You run the following queries frequently. Both queries must be able to use a columnstore index: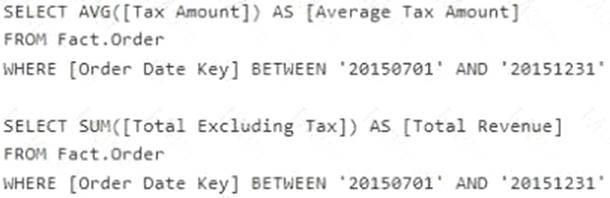
You need to ensure that the queries complete as quickly as possible.
Solution: You create one columnstore index that includes the [Order Date Key], [Tax Amount], and [Total Excluding Tax] columns.
Does the solution meet the goal?
- A. Yes
- B. No
Answer: A
Explanation:
You should use a columnstore index.
Columnstore indexes are the standard for storing and querying large data warehousing fact tables. This index uses column-based data storage and query processing to achieve gains up to 10 times the query performance in your data warehouse over traditional row-oriented storage.
References:
https://docs.microsoft.com/en-us/sql/relational-databases/indexes/columnstore-indexes-overview?view=sql-serv
NEW QUESTION 11
You are building a server to host a data warehouse.
The planned disk activity for-khe data warehouse is five percent write activity and 95 percent read activity. You need to recommend a storage solution for the data files of the data warehouse. The solution must meet the following requirements:
*Ensure that the data warehouse is available if two disks fail.
*Minimize hardware costs.
Which RAID configuration should you recommend?
- A. RAID1
- B. RAID 5
- C. RAID 6
- D. RAID 10
Answer: C
Explanation:
According to the Storage Networking Industry Association (SNIA), the definition of RAID 6 is: "Any form of RAID that can continue to execute read and write requests to all of a RAID array's virtual disks in the presence of any two concurrent disk failures."
NEW QUESTION 12
You are developing a Microsoft SQL Server Data Warehouse. You use SQL Server Integration Services (SSIS) packages to import files from a Microsoft Azure blob storage to the data warehouse.
You plan to use multiple SQL Server instances and SSIS Scale Out to complete the workload faster. You must configure three SQL Server instances to run the SSIS package.
Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A. Install The SSIS Scale Out Worker feature on two server
- B. Install the Scale Out Master role feature on one server.
- C. Deploy the SSIS project to the SSIS catalog only on the SQL Server which has the Scale Out Master role installed.
- D. Install the SSIS Scale Out Worker feature on all three server
- E. Install the Scale Out Master role on one server.
- F. Deploy the SSIS project to the SSIS catalog on all three SQL Servers in the SSIS Scale Out environment.
Answer: AD
NEW QUESTION 13
You have a Microsoft SQL Server Integration Services (SSIS) package that contains a Data Flow task as shown in the Data Flow exhibit. (Click the Exhibit button.)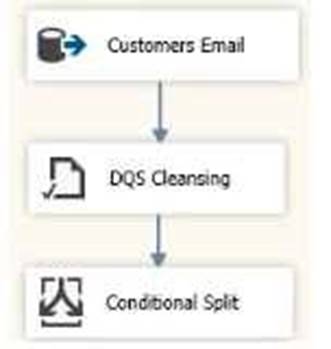
You install Data Quality Services (DQS) on the same server that hosts SSIS and deploy a knowledge base to manage customer email addresses. You add a DQS Cleansing transform to the Data Flow as shown in the Cleansing exhibit. (Click the Exhibit button.)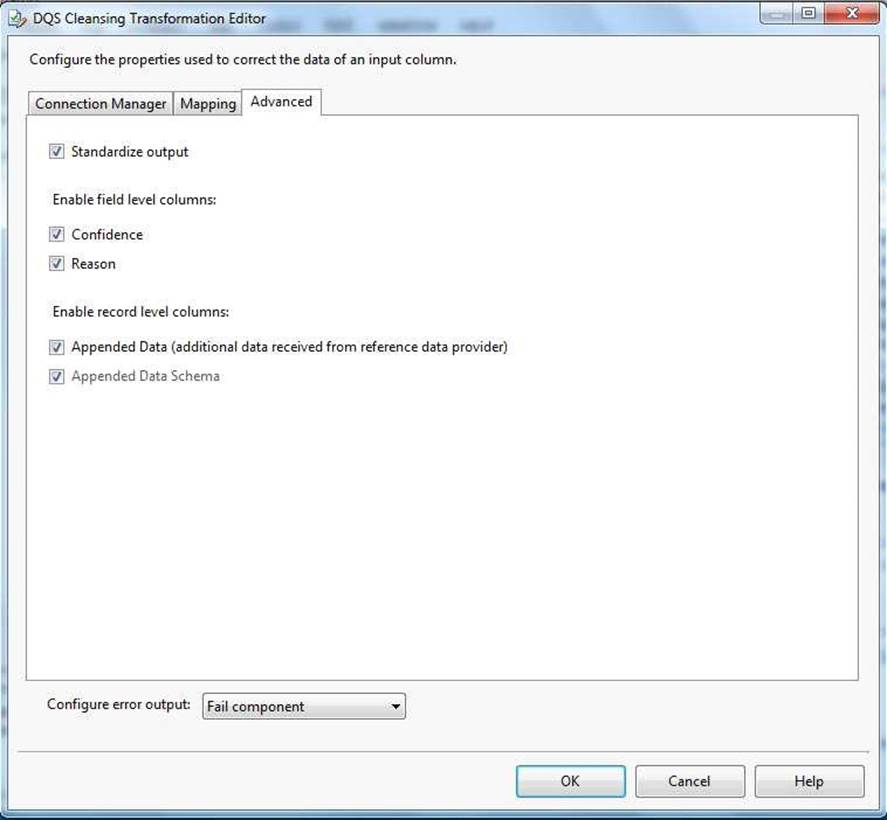
You create a Conditional Split transform as shown in the Splitter exhibit. (Click the Exhibit button.)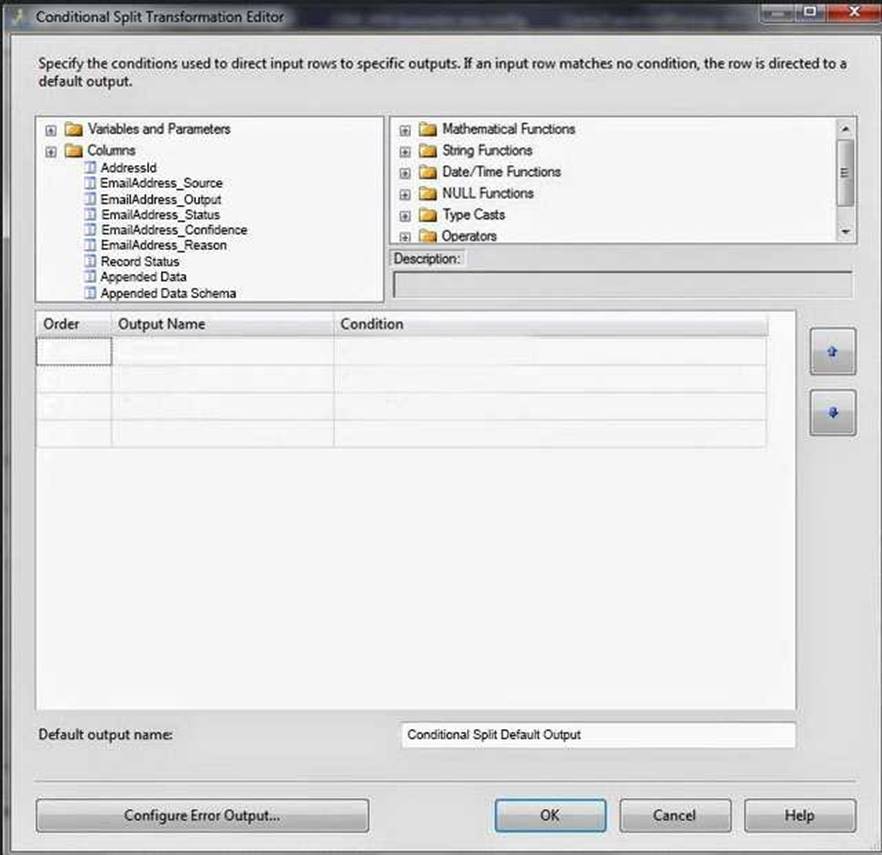
You need to split the output of the DQS Cleansing task to obtain only Correct values from the EmailAddress column.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
The DQS Cleansing component takes input records, sends them to a DQS server, and gets them back corrected. The component can output not only the corrected data, but also additional columns that may be useful for you. For example - the status columns. There is one status column for each mapped field, and another one that aggregated the status for the whole record. This record status column can be very useful in some scenarios, especially when records are further processed in different ways depending on their status. Is such cases, it is recommended to use a Conditional Split component below the DQS Cleansing component, and configure it to split the records to groups based on the record status (or based on other columns such as specific field status).
References: https://blogs.msdn.microsoft.com/dqs/2011/07/18/using-the-ssis-dqs-cleansing-component/
NEW QUESTION 14
You have a Microsoft SQL Server Integration Services (SSIS) package that loads data into a data warehouse each night from a transactional system. The package also loads data from a set of Comma-Separated Values (CSV) files that are provided by your company’s finance department.
The SSIS package processes each CSV file in a folder. The package reads the file name for the current file into a variable and uses that value to write a log entry to a database table.
You need to debug the package and determine the value of the variable before each file is processed.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
You debug control flows.
The Foreach Loop container is used for looping through a group of files. Put the breakpoint on it.
The Locals window displays information about the local expressions in the current scope of the Transact-SQL debugger.
References: https://docs.microsoft.com/en-us/sql/integration-services/troubleshooting/debugging-control-flow
http://blog.pragmaticworks.com/looping-through-a-result-set-with-the-foreach-loop
NEW QUESTION 15
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You are developing a Microsoft SQL Server Integration Services (SSIS) package. The package design consists of two differently structured sources in a single data flow. The Sales source retrieves sales transactions from a SQL Server database, and the Product source retrieves product details from an XML file.
You need to combine the two data flow sources into a single output dataset. Which SSIS Toolbox item should you use?
- A. CDC Control task
- B. CDC Splitter
- C. Union All
- D. XML task
- E. Fuzzy Grouping
- F. Merge
- G. Merge Join
Answer: G
Explanation:
The Merge Join transformation provides an output that is generated by joining two sorted datasets using a FULL, LEFT, or INNER join. For example, you can use a LEFT join to join a table that includes product information with a table that lists the country/region in which a product was manufactured. The result is a table that lists all products and their country/region of origin.
References:
https://docs.microsoft.com/en-us/sql/integration-services/data-flow/transformations/merge-join-transformation
NEW QUESTION 16
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You have a database named DB1 that has change data capture enabled.
A Microsoft SQL Server Integration Services (SSIS) job runs once weekly. The job loads changes from DB1 to a data warehouse by querying the change data capture tables.
You remove the Integration Services job.
You need to stop tracking changes to the database. The solution must remove all the change data capture configurations from DB1.
Which stored procedure should you execute?
- A. catalog.deploy_project
- B. catalog.restore_project
- C. catalog.stop.operation
- D. sys.sp.cdc.addjob
- E. sys.sp.cdc.changejob
- F. sys.sp_cdc_disable_db
- G. sys.sp_cdc_enable_db
- H. sys.sp_cdc.stopJob
Answer: F
NEW QUESTION 17
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
Your company uses Microsoft SQL Server to deploy a data warehouse to an environment that has a SQL Server Analysis Services (SSAS) instance. The data warehouse includes the Fact.Order table as shown in the following table definition. The table has no indexes.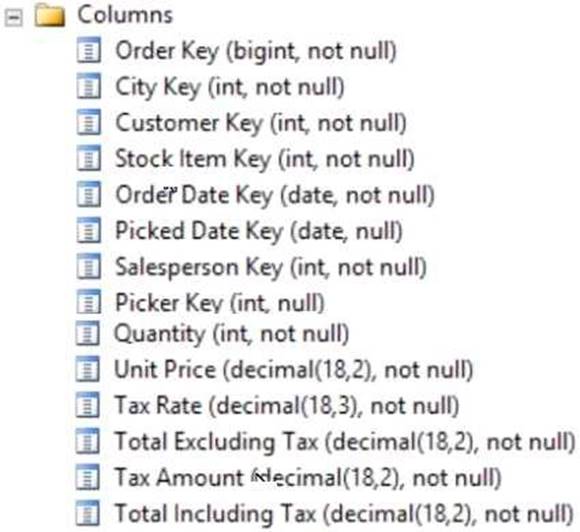
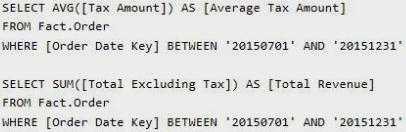
You need to ensure that the queries complete as quickly as possible.
Solution: You create measure for the Fact.Order table. Does the solution meet the goal?
- A. Yes
- B. No
Answer: B
Explanation:
You should use a columnstore index.
Columnstore indexes are the standard for storing and querying large data warehousing fact tables. This index uses column-based data storage and query processing to achieve gains up to 10 times the query performance in your data warehouse over traditional row-oriented storage.
References:
https://docs.microsoft.com/en-us/sql/relational-databases/indexes/columnstore-indexes-overview?view=sql-serv
NEW QUESTION 18
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You are developing a Microsoft SQL Server Integration Services (SSIS) package.
You need to ensure that the packa
ge records the current Log Sequence Number (LSN) in the source database before the package begins reading source tables.
Which SSIS Toolbox item should you use?
- A. CDC Control task
- B. CDC Splitter
- C. Union All
- D. XML task
- E. Fuzzy Grouping
- F. Merge
- G. Merge Join
Answer: A
Explanation:
The CDC Control task is used to control the life cycle of change data capture (CDC) packages. It handles CDC package synchronization with the initial load package, the management of Log Sequence Number (LSN) ranges that are processed in a run of a CDC package.
References: https://docs.microsoft.com/en-us/sql/integration-services/control-flow/cdc-control-task
NEW QUESTION 19
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You have a database named DB1 that has change data capture enabled.
A Microsoft SQL Server Integration Services (SSIS) job runs once weekly. The job loads changes from DB1 to a data warehouse by querying the change data captule tables.
You remove the Integration Services job.
You need to stop tracking changes to the database temporarily. The solution must ensure that tracking changes can be restored quickly in a few weeks.
Which stored procedure should you execute?
- A. catalog.deploy_project
- B. catalog.restore_project
- C. catalog.stop.operation
- D. sys.sp_cdc.addJob
- E. sys.sp.cdc.changejob
- F. sys.sp_cdc_disable_db
- G. sys.sp_cdc_enable_db
- H. sys.sp_cdc.stopJob
Answer: C
Explanation:
catalog.stop_operation stops a validation or instance of execution in the Integration Services catalog.
References:
https://docs.microsoft.com/en-us/sql/integration-services/system-stored-procedures/catalog-stop-operation-ssisd
NEW QUESTION 20
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You are a database administrator for an e-commerce company that runs an online store. The company has the databases described in the following table.
Product prices are updated and are stored in a table named Products on DB1. The Products table is deleted and refreshed each night from MDS by using a Microsoft SQL Server Integration Services (SSIS) package. None of the data sources are sorted.
You need to update the SSIS package to add current prices to the Products table. What should you use?
- A. Lookup transformation
- B. Merge transformation
- C. Merge Join transformation
- D. MERGE statement
- E. Union All transformation
- F. Balanced Data Distributor transformation
- G. Sequential container
- H. Foreach Loop container
Answer: D
Explanation:
In the current release of SQL Server Integration Services, the SQL statement in an Execute SQL task can contain a MERGE statement. This MERGE statement enables you to accomplish multiple INSERT, UPDATE, and DELETE operations in a single statement.
References:
https://docs.microsoft.com/en-us/sql/integration-services/control-flow/merge-in-integration-services-packages
NEW QUESTION 21
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it As a result these questions will not appear in the review screen.
You are the administrator of a Microsoft SQL Server Master Data Services (MDS) instance. The instance contains a model named Geography and a model named customer. The Geography model contains an entity named countryRegion.
You need to ensure that the countryRegion entity members are available in the customer model.
Solution: In the Customer model, add a domain-based attribute to reference the CountryRegion entity in the Geography model.
Does the solution meet the goal?
- A. Yes
- B. No
Answer: A
NEW QUESTION 22
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in the series.
Start of repeated scenario
Contoso. Ltd. has a Microsoft SQL Server environment that includes SQL Server Integration Services (SSIS), a data warehouse, and SQL Server Analysis Services (SSAS) Tabular and multidimensional models.
The data warehouse stores data related to your company sales, financial transactions and financial budgets. All data for the data warenouse originates from the company's business financial system.
The data warehouse includes the following tables: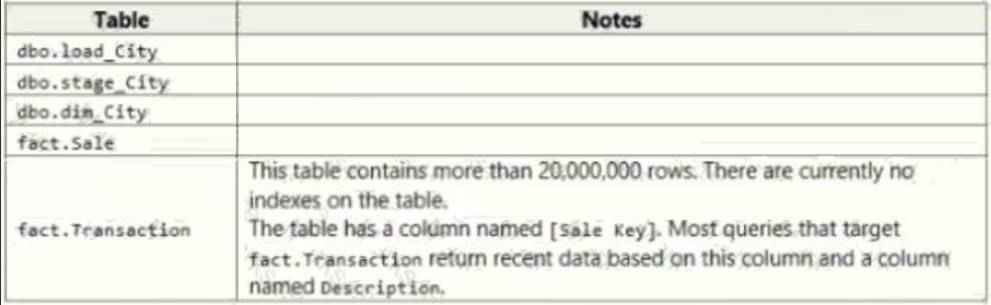
The company plans to use Microsoft Azure to store older records from the data warehouse. You must modify the database to enable the Stretch Database capability.
Users report that they are becoming confused about which city table to use for various queries. You plan to create a new schema named Dimension and change the name of the dbo.du_city table to Diamension.city. Data loss is not permissible, and you must not leave traces of the old table in the data warehouse.
Pal to create a measure that calculates the profit margin based on the existing measures.
You must implement a partitioning scheme few the fact. Transaction table to move older data to less expensive storage. Each partition will store data for a single calendar year, as shown in the exhibit (Click the Exhibit button.) You must align the partitions.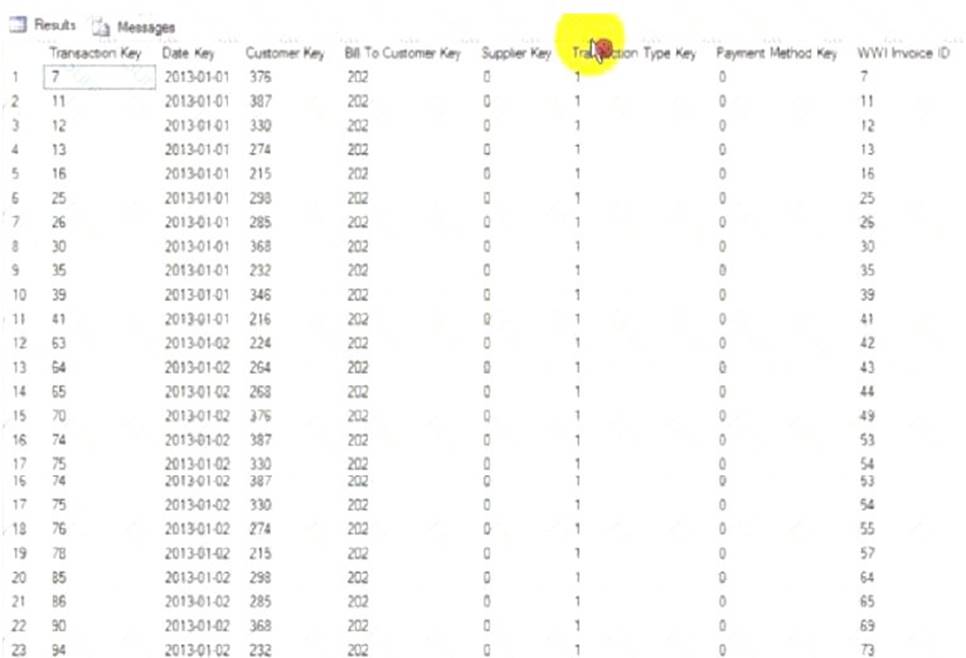
You must improve performance for queries against the fact.Transaction table. You must implement appropriate indexes and enable the Stretch Database capability.
End of repeated scenario
You need to resolve the problems reported about the dia city table.
How should you complete the Transact-SQL statement? To answer, drag the appropriate Transact-SQL segments to the correct locations. Each Transact-SQL segment may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.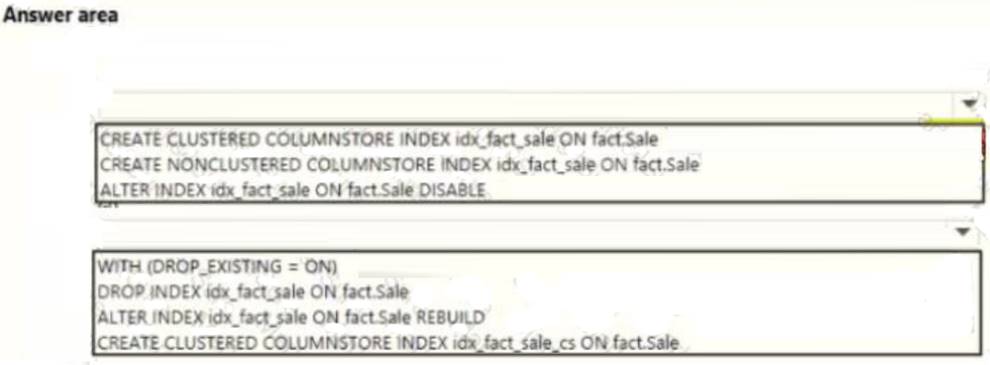
- A. Mastered
- B. Not Mastered
Answer: A
Explanation: 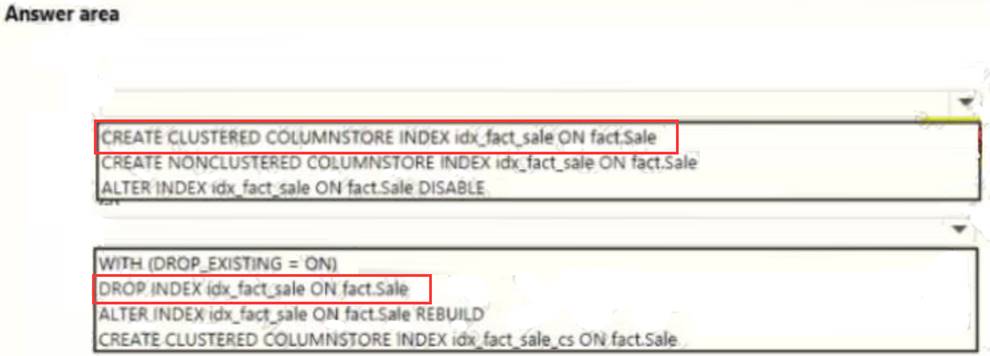
NEW QUESTION 23
You have a series of analytic data models and reports that provide insights into the participation rates for sports at different schools. Users enter information about sports and participants into a client application. The application stores this transactional data in a Microsoft SQL Server database. A SQL Server Integration Services (SSIS) package loads the data into the models.
When users enter data, they do not consistently apply the correct names for the sports. The following table shows examples of the data entry issues.
You need to improve the quality of the data.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
References: https://docs.microsoft.com/en-us/sql/data-quality-services/perform-knowledge-discovery
NEW QUESTION 24
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
Your company uses Microsoft SQL Server to deploy a data warehouse to an environment that has a SQL Server Analysis Services (SSAS) instance. The data warehouse includes the Fact.Order table as shown in the following table definition. The table has no indexes.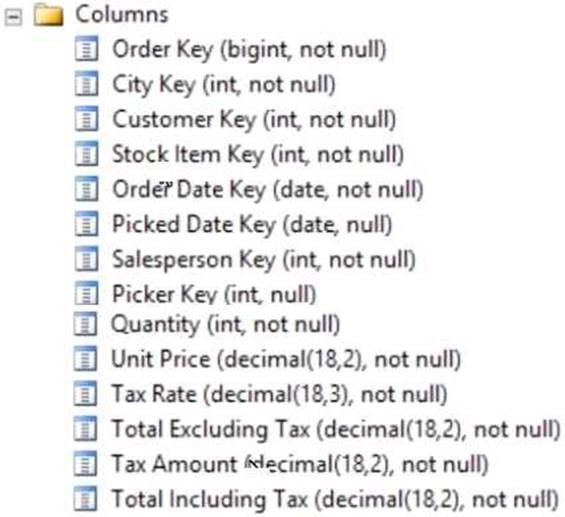
You must minimize the amount of space that indexes for the Fact.Order table consume. You run the following queries frequently. Both queries must be able to use a columnstore index:
You need to ensure that the queries complete as quickly as possible.
SolutionvYou create two nonclustered indexes. The first includes the [Order Date Key] and [Tax Amount] columns. The second will include the [Order Date Key] and [Total Excluding Tax] columns.
Does the solution meet the goal?
- A. Yes
- B. No
Answer: B
NEW QUESTION 25
......
100% Valid and Newest Version 70-767 Questions & Answers shared by Certshared, Get Full Dumps HERE: https://www.certshared.com/exam/70-767/ (New 160 Q&As)
- Updated Microsoft 70-346 practice test
- The Secret of Microsoft 70-464 exam dumps
- 10 Tips For Up to the immediate present 70-487 pdf
- Microsoft AZ-100 Free Practice Questions 2021
- Up To The Immediate Present MS-101 Paper 2021
- What Refined 70-499 dumps Is?
- Microsoft AZ-102 Dumps Questions 2021
- Microsoft AZ-202 Exam Dumps 2021
- All About 100% Correct 70-467 vce
- Highest Quality Microsoft DP-203 Exams Online